Опубликована полная последовательность человеческого генома
Молекулярные биологи закончили собирать последовательность ДНК человека — этому посвящен специальный выпуск журнала Science. В предыдущей версии генома, которая появилась в 2001 году, около 8 процентов последовательности оставались нерасшифрованными. Это в основном некодирующие участки, центральные и концевые области хромосом. Результатам проекта посвящены сразу шесть (1, 2, 3, 4, 5, 6) статей. Полная версия генома позволяет точнее выявлять индивидуальные генетические особенности людей и может стать новым стандартом в генетике, несмотря на то, что в ней пока не хватает целой хромосомы.
В 2000 году проект «Геном человека» и компания Крейга Вентера Celera genomics заявили о том, что закончили секвенировать последовательность человеческой ДНК (подробнее об этом мы рассказывали в тексте «Геном человека: двадцать лет спустя»). К 2001 году они опубликовали свои черновые версии сборки с разницей в сутки (сначала «Геном человека», потом проект Вентера), а к 2003 году объединили свои усилия и наработки, чтобы собрать единый чистовик. Он стал первым стандартом, или референсным геномом, с которым сверялись все, кто расшифровывал новые геномы человека или искал генетические причины болезней. Однако работа по чтению человеческой ДНК на этом не закончилась.
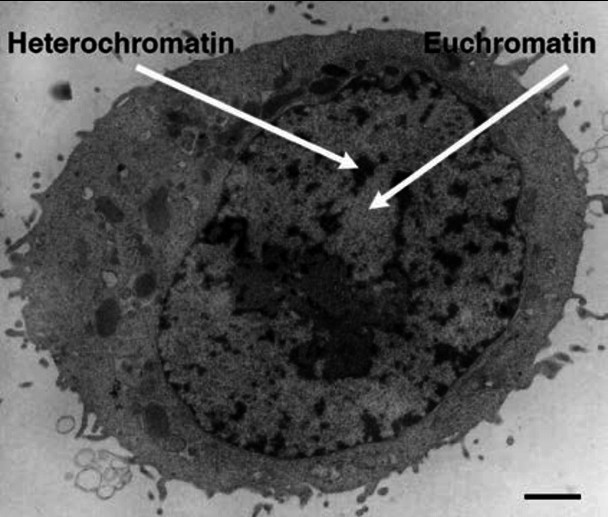
Авторы первой версии человеческого генома не скрывали, что он далеко не полон. Например, в нем остался 341 пробел. Кроме того, в своей работе исследователи сделали ставку на эухроматин — ту фракцию ДНК, которая в клетке обычно находится в неплотно упакованном состоянии и информация с которой может быть считана. Таким образом, в первый вариант генома не вошли многие участки гетерохроматина — «скрученной» фракции ДНК. Она состоит в основном из последовательностей, которые не кодируют белки, но выполняют разные технические и структурные (и часто не до конца понятные) функции — поэтому тоже могут влиять на жизнь и работу клетки.
В первом варианте генома также не до конца было ясно, какие гены и некодирующие участки за что отвечают. Выяснением этого занимается, например, проект ENCODE. Наконец, референсный геном не учитывал в полной мере генетическое разнообразие людей — несмотря на то, что его собрали из случайных количеств ДНК от нескольких десятков человек. Восполнять эти пробелы взялись другие проекты, например, «Тысяча геномов».