Внимание, черный ящик. Как и зачем исследовать логику нейросетей
Как и зачем исследовать логику нейросетей
Прогресс в машинном обучении, достигнутый за последнее десятилетие, подарил нам как множество новых возможностей, так и неочевидные проблемы: модели машинного обучения стали настолько сложными и большими, что понять логику их действий все труднее. Вместе с Yandex Research, который проводит исследования машинного обучения мирового уровня, рассказываем, как разработчики изучают современные ML-алгоритмы — и почему это стоит делать, даже если они работают хорошо.
Начало обучения
Нейросети на слуху последние несколько лет. Может показаться, что это новый тип алгоритмов. Отчасти так оно и есть: многие архитектуры нейросетей, успевшие стать классическими, появились лишь несколько лет назад. Но идея повторить в машине принцип работы нейронных сетей была реализована на самой заре машинного обучения.
В конце 1950-х годов Фрэнк Розенблатт описал и реализовал «в железе» перцептрон — простейшую архитектуру искусственных нейросетей, которая заложила основу для современных нейросетей (а многослойные перцептроны широко применяются до сих пор).
Розенблатт показал работу перцептрона, обучив его распознавать знаки и символы, что для 1958 года было серьезным успехом. Но, пожалуй, главное достижение и следствие этого заключалось в укреплении идеи, что для создания машины инженеру не нужно вручную прописывать набор правил — они могут родиться сами в виде весов во время обучения.
В дальнейшем ученые придумывали все новые и новые архитектуры моделей машинного обучения, причем не только нейросетевые. И хотя математические операции внутри моделей по отдельности оставались понятными, их количество и взаимное влияние усложняло анализ работы алгоритмов.
Старший исследователь Yandex Research Андрей Малинин объясняет: «Представьте огромный часовой механизм размером с небоскреб, внутри которого крутятся миллиарды шестеренок размером в ноготь — все красиво крутится, но ничего не понятно. Мы можем посмотреть на какой-то локальный кусочек с парой шестеренок, и вроде ясно, как в нем все работает, но неясно, как это встраивается в механизм в целом».
Современная эра
В 2012 году в развитии машинного обучения наметился прорыв, связанный с нейросетью AlexNet. Это сверточная нейросеть для классификации изображений из датасета ImageNet, в котором содержится более 15 миллионов изображений объектов, разбитых на 22 тысячи категорий. Задача бенчмарка ImageNet — определить класс объекта на фотографии. AlexNet удалось выиграть соревнования ImageNet 2012 года, причем с большим отрывом от ближайшего конкурента: частота ошибок при определении пяти самых вероятных объектов составила 15,3 процента против 26,2 у алгоритма со второго места.
Такой успех можно объяснить несколькими причинами. Во-первых, разработчики улучшили архитектуру нейросети, использовав в качестве функции активации редкую для того времени и повсеместно применяемую сейчас ReLU. Во-вторых, хотя это была большая нейросеть, состоявшая из 650 тысяч нейронов и имевшая 60 миллионов параметров, разработчики нашли способ ускорить ее обучение. Они сумели распараллелить обучение сети на два графических процессора. Это была не первая работа, в которой нейросети предлагали обучать на графических процессорах, но, вероятно, первый заметный пример, который показал другим исследователям, что ограничения по вычислительной мощности, сдерживавшие развитие этой области, можно обойти. А значит, размеры моделей и обучающих датасетов можно смело увеличивать.
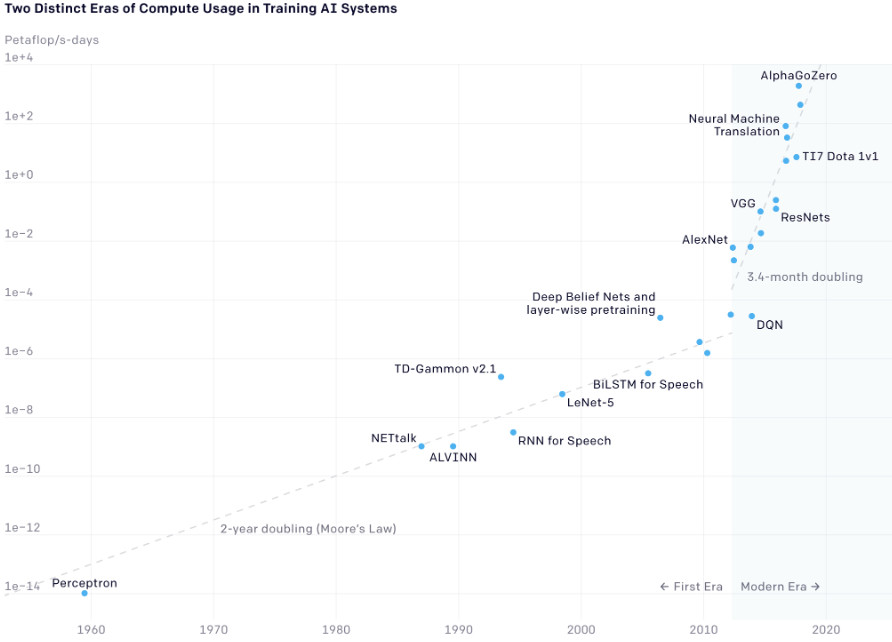
Спустя шесть лет исследователи из OpenAI проанализировали ключевые работы в области нейросетей и показали, что именно с AlexNet в 2012 году начался рост затрачиваемой на обучение вычислительной мощности. Если раньше она удваивалась каждые два года, следуя закону Мура, то с 2012 года удвоение происходило уже каждые 3–4 месяца. Благодаря такой четкой временной границе OpenAI предложила называть период после 2012 года «современной эрой».
Вместе с увеличением размера нейросетей менялись и подходы к обучению. Стало набирать популярность обучение без учителя на неразмеченных данных.
Хороший пример такого подхода — нейросети GPT, разработанные в OpenAI. Это модели генерации текста, задача которых сводится к предсказанию следующего слова в предложении. Это позволяет писать большие тексты, которые выглядят как результат работы человека, а не машины. Разработчики GPT решили уйти от обучения на ограниченных датасетах с размеченными текстами к самообучению на гигантском объеме самых разных текстов из интернета: GPT-3 обучили на 570 гигабайт текстов. Это позволило модели выучить структуру языка, после чего ее можно быстро дообучить для конкретной задачи, например генерации стихов в стиле любимого поэта, показав всего несколько примеров, а не собирая новый большой датасет.